大数据实验报告Windows环境下安装Spark及RDD编程和Spark编程实现wordcount.doc
”大数据实验 安装spark RDD编程 Spark编程 wordcount“ 的搜索结果

注意:需要先在hadoop分布式文件系统中创建文件1.先在本地文件系统创建data.txt文件2.启动hadoop分布式文件系统3.上传本地文件data.txt到hadoop分布式文件系统查看分布式文件系统中是否存在data.txt。
1、hashpartitioner源码解读case _ =>false2、自定义分区器要实现自定义分区器,需要继承org.apache.spark.partitioner类,并实现下面三个方法。1)numpartitions:int:返回创建出来的分区数2)getpartition(key:...
Spark RDD编程 文件数据读写
Scala编程语言是Spark的首选编程语言之一。Spark最初是用Scala编写的,而且Scala具有强大的静态类型系统和函数式编程特性,使其成为Spark的理想选择。Spark支持多种编程语言,包括JavaPython和R。


//方式4 map + aggregateByKey //方式5 map + foldByKey //方式6map + combineByKey
上篇:第 2 章大数据SparkCore的RDD编程案例(中) Action 1、reduce(func)案例 作用:通过func函数聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据。 需求:创建一个RDD,将所有元素聚合得到结果。 (1...
上篇:第2章 大数据技术之SparkCore的RDD编程(上) 一、案例操作 1、repartition(numPartitions) 案例 作用:根据分区数,重新通过网络随机洗牌所有数据。 需求:创建一个4个分区的RDD,对其重新分区 操作步骤: ...
collect算子:将RDD各个分区内的数据,统一收集到Driver中,形成一个List对象。RDD是分布式对象,数据量可以很大,所以用这个算子之前需要知道如果数据集结果很大,就会把driver内存撑爆,出现oom。结果如下图所示在...
由于一行为一条记录,先对数据进行切分构成二元组(时间,用户),然后按照用户进行分组,得到分组后的数据,取第一条数据为该用户第一次出现的数据,然后按照时间进行分组,最后输出结果。...首先我们先对原始数据进行...





(1)基于排序机制的wordcount程序 对于以下文件 进行wordcount,并按照出现次数多少排序 代码如下: /** * 排序的wordcount程序 * @author Administrator * */ public class SortWordCount { public static ...
二、RDD编程 2.1创建RDD的⼆种⽅式: 1.从集合中创建RDD 2.从外部存储创建RDD 2.2Transformation算⼦ RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些 应⽤到基础数据...
spark-core中常用代码块
第十五周 Spark编程基础实例——wordCount编程 Shell下编写wordCount 测试文件 创建一个本地文件word.txt,内含多行文本,每行文本由多个单词构成,单词之间用空格分隔,编写spark程序统计每个单词出现的...


学习任何一门语言,都是从helloword开始,对于大数据框架来说,则是从wordcount开始,Spark也不例外,作为一门大数据处理框架,在系统的学习spark之后,wordcount可以有11种方式实现,你知道的有哪些呢?还等啥,不...
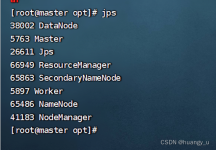
按照讲义中json数据的生成及分析,复现实验,并适当分析。0.2 讲义kafka源,2字母单词分析任务按照讲义要求,复现kafka源实验。0.3 讲义socket源,结构化流实现词频统计。按照讲义要求,复现socket源实验。0.4(不选...
//方式1 map + reduceByKey。 //方式2 map + groupByKey + mapValues。 //方式3 groupBy + mapValues。
实验步骤: 1、Scala安装与环境配置 ①Scala文件解压、重命名 输入:tar -xvf scala-2.12.2.tgz 然后移动到/opt/scala 里面,重命名为 输入: mv scala-2.12.2 /opt/scala mv scala-2.12.2 scala2.12 ②环境...

推荐文章
- Android RIL框架分析-程序员宅基地
- Python编程基础:第六节 math包的基础使用Math Functions_ps math function-程序员宅基地
- canal异常 Could not find first log file name in binary log index file_canal could not find first log file name in binary-程序员宅基地
- 【练习】生成10个1到20之间的不重复的随机数并降序输出-程序员宅基地
- linux系统扩展名大全,Linux系统文件扩展名学习-程序员宅基地
- WPF TabControl 滚动选项卡_wpf 使用tabcontrol如何给切换的页面增加滚动条-程序员宅基地
- Apache Jmeter常用插件下载及安装及软硬件性能指标_jmeter插件下载-程序员宅基地
- SpringBoot 2.X整合Mybatis_springboot2.1.5整合mybatis不需要配置mapper-locations-程序员宅基地
- ios刷android8.0,颤抖吧 iOS, Android 8.0正式发布!-程序员宅基地
- 【halcon】C# halcon 内存暴增_halcon 读二维码占内存-程序员宅基地